ディープラーニングは、画像認識に高い性能を示したことが最初の成功となりました。一般的な画像認識には、分類(classificaion)、検知(object detection)、セグメンテーション(segmentation)がありますが、本日は検知についてお話したく。
画像認識における検知とは画像の中から、複数の認識対象を検出することをいいます。こんな感じ。
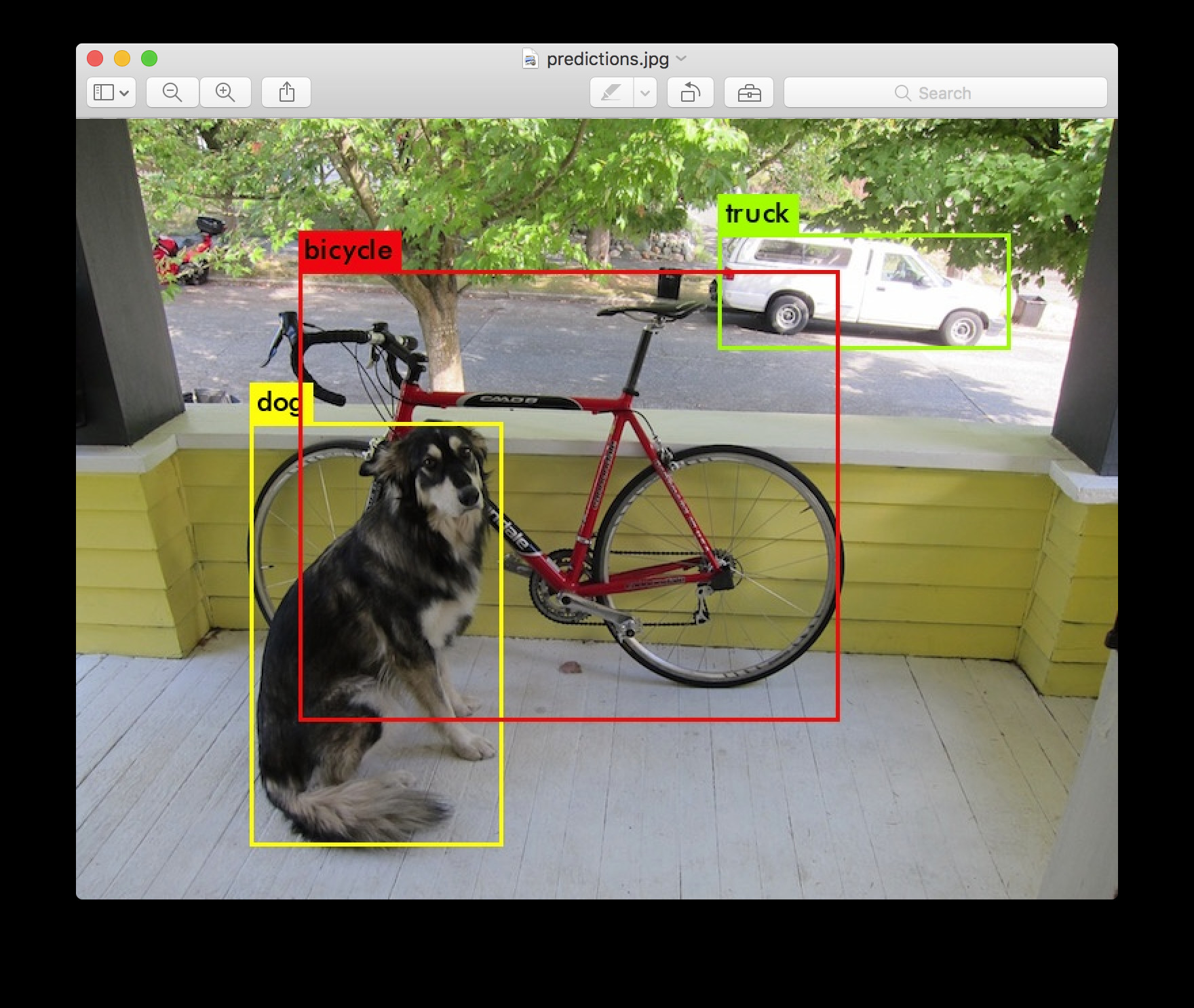
ディープラーニングによる画像検知の実装はいくつかあり、人気のあるものとしてYoloがあります。
無骨にCで実装されており、ほとんどJoseph Redmon氏がひとりで作った感があって、いろいろすごいです笑
Josephさん、Tedにも出ているのでどうぞ!
https://www.ted.com/talks/joseph_redmon_how_a_computer_learns_to_recognize_objects_instantly?language=ja
Yoloは高い認識性能と高速動作を両立していることが特徴です。難点としてはドキュメントがほとんどないことでしょうか。Josephさんの助けを期待してはいけません。なのでユーザがソースを読んだりして、その使い方を共有していくのが利用スタイルとなっています。
Yoloは高い認識性能と高速動作を両立していることが特徴です。難点としてはドキュメントがほとんどないことでしょうか。Josephさんの助けを期待してはいけません。なのでユーザがソースを読んだりして、その使い方を共有していくのが利用スタイルとなっています。
Sigfossでは比較的初期の頃からYoloを使ったシステムを組んでいて、v2ではパラメータを色々変更しては精度や速度を測定してきました。Yolo君がお気に入りなのです。
最近、そんなYoloに待望の新バージョンv3が公開されました。Yolo v2と比べてスピードの落ち込みを抑えながら精度の向上を狙ったものです。率直な印象としては(本人も言ってますが)Yolo v1 -> v2のような大きな変更はありません。一番大きな変更としてはベースとなっているCNNのネットワークモデルが、VGGベースのDarknet19からResNetベースのDarknet53に変わったことだと思っています。
もちろん早速v3を使ってみていることは言うまでもありません。v2に比べてのv3の精度ですが、手元の実験では今のところ目立って良好な結果がでていません。それなりに使い方のポイントがあるのかと思いますので、その辺りは今後ご紹介できたらと思います。
さて、このv3、学習と推測の方法には大きな変更はないのですが、cfgファイルには設定法に変更がある部分があります。
さて、このv3、学習と推測の方法には大きな変更はないのですが、cfgファイルには設定法に変更がある部分があります。
Yolo v2では最終段のfiltersの数は、class数とanchorboxの数がそれぞれcnとanだったときに
(cn+5) x an
でした。(anはデフォルトで5)
これがYolo v3では[yolo]layerの前のfiltersの数(defaultで三箇所)を
(cn+ 5) x 3
とします。加えて以下の部分、Yolo v2では学習時の設定のままでも推測が可能だったのですが、Yolo v3では推測時用の設定しないとうまく推測が動きませんので注意ください。
# 推測時
batch=1
subdivisions=1
# 学習時(例)
# batch=64
# subdivisions=16
その他アンカーボックスの値の定義が変更になりました。アンカーボックスを計算し直すときには注意が必要です。
#アンカーボックスを計算しなおす方法については次回以降でご紹介できたらと思います。
RoboCupでもYoloを使っているチームが多いと話題になってましたが、v3の使い所がわかってさらに精度が出せるようになるといいなと思っている今日この頃なのでした。